Predicting classes with classification
Classification is a machine learning process that predicts the class or category of a data point in a data set. For a simple example, consider how the shapes in the following graph can be differentiated and classified as "circles" and "triangles":
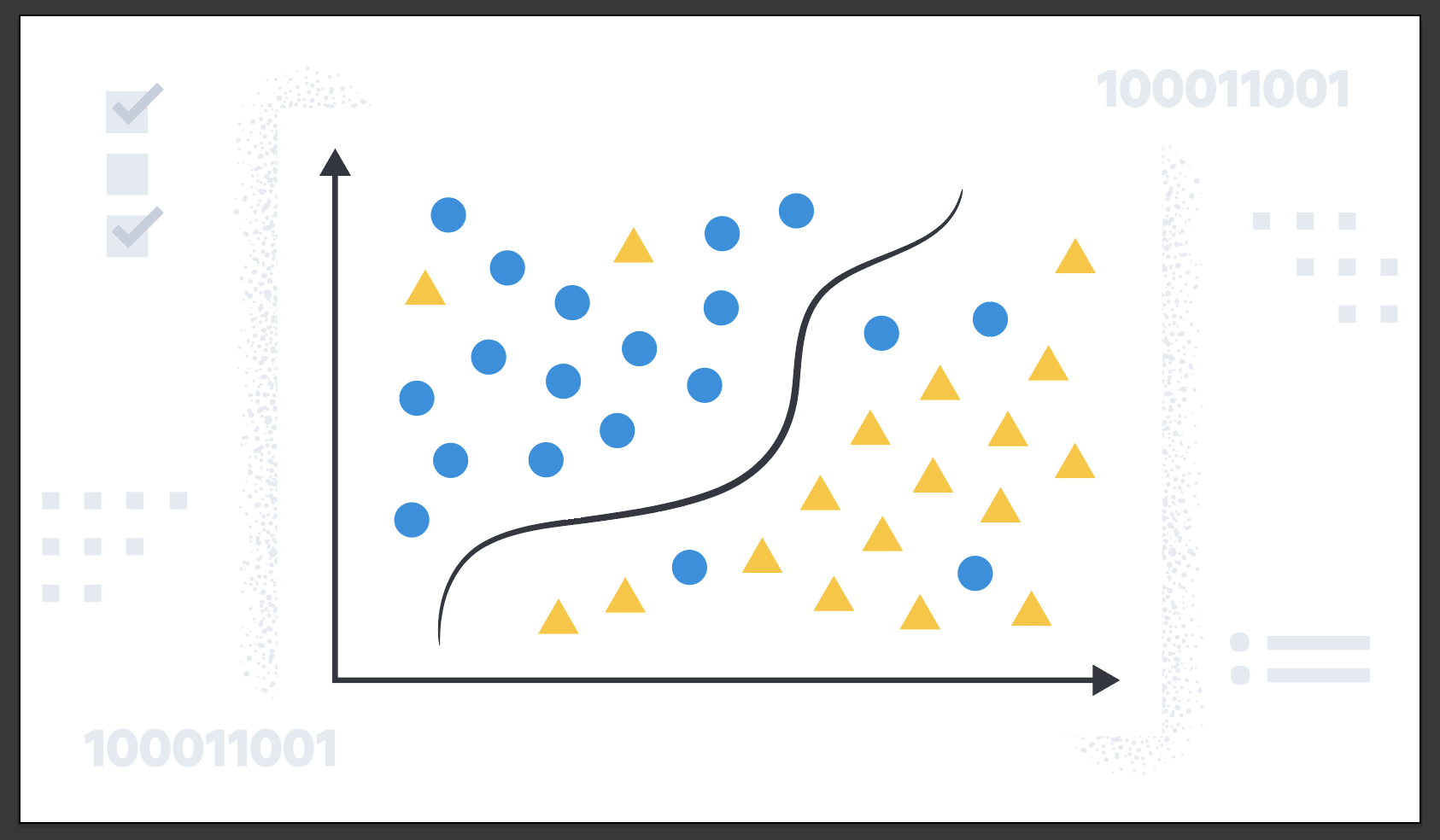
In reality, classification problems are more complex, such as classifying malicious and benign domains to detect DGA activities for security reasons or predicting customer churn based on customer calling data. Classification is for predicting discrete, categorical values.
When you create a classification job, you must specify which field contains the classes that you want to predict. This field is known as the dependent variable. It can contain maximum 100 classes. By default, all other supported fields are included in the analysis and are known as feature variables. You can optionally include or exclude fields. For more information about field selection, refer to the explain data frame analytics API.
Classification algorithms
Classification analysis uses an ensemble algorithm that is similar to extreme gradient boosting (XGBoost) which combines multiple weak models into a composite one. It uses decision trees to learn to predict the probability that a data point belongs to a certain class. XGBoost trains a sequence of decision trees and every decision tree learns from the mistakes of the forest so far. In each iteration, the trees added to the forest improve the decision quality of the combined decision forest. The classification algorithm optimizes for a loss function called cross-entropy loss.
1. Define the problem
Classification can be useful in cases where discrete, categorical values needs to be predicted. If your use case requires predicting such values, then classification might be the suitable choice for you.