Spiegazione del punteggio di anomalia
Ad ogni anomalia viene assegnato un punteggio di anomalia. Questo punteggio indica quanto è anomalo un dato punto, il che rende possibile definire la sua gravità rispetto ad altre anomalie. Questa pagina fornisce una spiegazione ad alto livello dei fattori critici considerati per il calcolo dei punteggi di anomalia, come vengono calcolati i punteggi e come funziona la rinormalizzazione.
Fattori di impatto del punteggio di anomalia
I lavori di rilevamento delle anomalie suddividono i dati delle serie temporali in intervalli di tempo (bucket). I dati all'interno di ogni bucket vengono aggregati utilizzando delle funzioni. Il rilevamento delle anomalie avviene sui valori dei bucket. Tre fattori possono influenzare il punteggio iniziale di anomalia di un record:
- impatto di un singolo bucket,
- impatto multi-bucket,
- impatto delle caratteristiche dell'anomalia.
Impatto di un singolo bucket
Per prima cosa viene calcolata la probabilità del valore effettivo nel bucket. Questa probabilità dipende da quanti valori simili sono stati osservati in passato. Di solito è legata alla differenza tra il valore effettivo e il valore tipico. Il valore tipico è il valore mediano della distribuzione di probabilità per il bucket. Questa probabilità porta all'impatto del singolo bucket, che solitamente domina il punteggio iniziale di anomalia in caso di un picco o calo breve.
Impatto multi-bucket
Le probabilità dei valori nel bucket attuale e nei precedenti 11 bucket contribuiscono all'impatto multi-bucket. Le differenze accumulate tra il valore effettivo e il valore tipico portano all'impatto multi-bucket sul punteggio iniziale di anomalia del bucket corrente. Un alto impatto multi-bucket indica un comportamento anomalo nell'intervallo che precede il bucket corrente, anche se il valore di questo bucket potrebbe rientrare nel 95% dell'intervallo di confidenza.
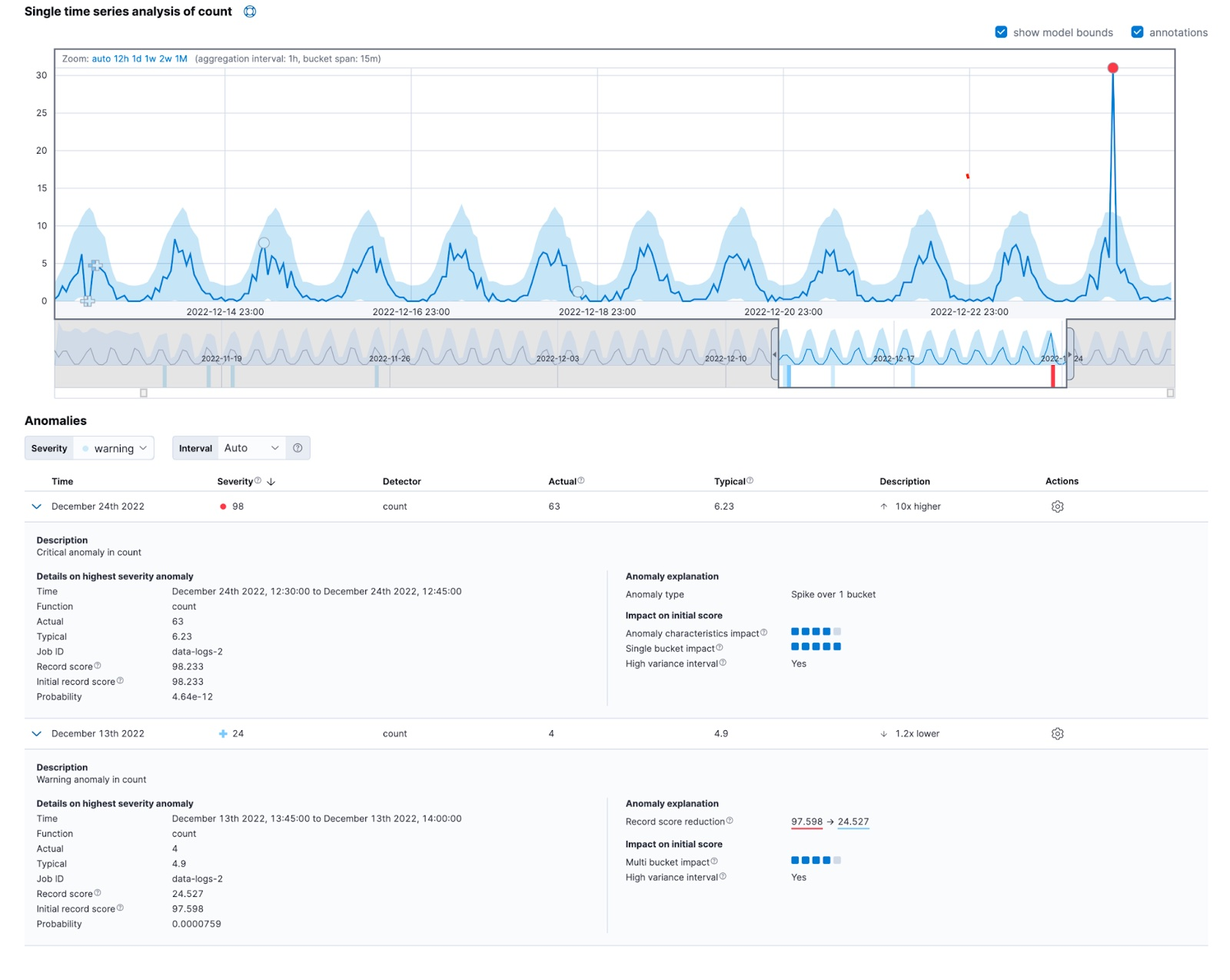
I segnali distintivi contrassegnano le anomalie con un alto impatto multi-bucket per evidenziare la differenza. Un segno più "+" rappresenta queste anomalie in Kibana, invece di un cerchio.
Impatto delle caratteristiche dell'anomalia
L'impatto delle caratteristiche dell'anomalia considera le diverse caratteristiche dell'anomalia, come la sua lunghezza e dimensione. La durata totale dell'anomalia viene presa in considerazione, e non un intervallo fisso come nel caso del calcolo dell'impatto multi-bucket. La lunghezza potrebbe essere di un solo bucket o di trenta (o più) bucket. Confrontando la lunghezza e la dimensione dell'anomalia con le medie storiche, è possibile adattarsi al dominio e ai modelli dei dati. Il comportamento predefinito dell'algoritmo è di assegnare punteggi più alti alle anomalie lunghe rispetto a picchi brevi. In pratica, le anomalie brevi si rivelano spesso errori nei dati, mentre le anomalie lunghe sono eventi ai quali potrebbe essere necessario reagire.
La combinazione dell'impatto multi-bucket e dell'impatto delle caratteristiche dell'anomalia porta a una rilevazione più affidabile dei comportamenti anomali su vari domini.
Riduzione del punteggio del record (rinormalizzazione)
I punteggi di anomalia sono compresi tra 0 e 100. I valori vicini a 100 indicano le anomalie più significative che il lavoro ha rilevato fino a quel momento. Per questo motivo, quando viene rilevata un'anomalia più grande di tutte quelle precedenti, i punteggi delle anomalie precedenti devono essere ridotti.
Il processo in cui l'algoritmo di rilevamento delle anomalie regola i punteggi di anomalia dei record passati quando arrivano nuovi dati è chiamato rinormalizzazione. Il parametro di configurazione renormalization_window_days specifica l'intervallo di tempo per questo aggiustamento. Il Single Metric Viewer in Kibana evidenzia il cambiamento di rinormalizzazione.
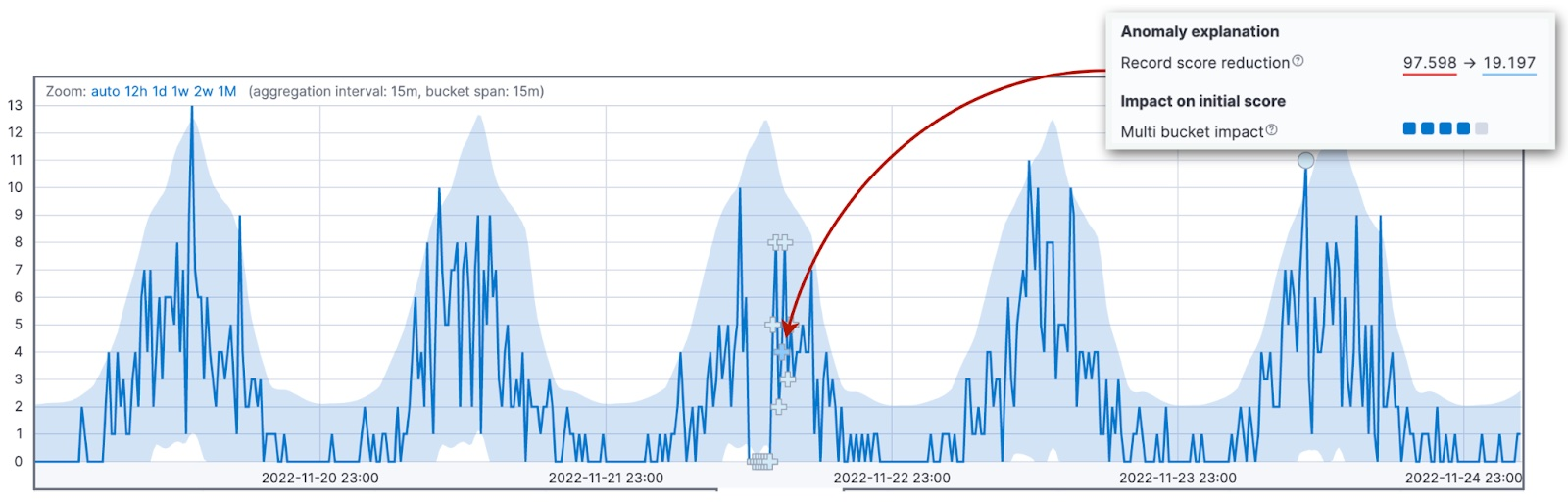
Altri fattori per la riduzione del punteggio
Altri due fattori possono portare alla riduzione del punteggio iniziale: un intervallo di alta variabilità e un bucket incompleto.
Il rilevamento delle anomalie è meno affidabile se l'attuale bucket fa parte di un pattern stagionale con alta variabilità nei suoi dati. Ad esempio, potresti avere lavori di manutenzione del server che vengono eseguiti ogni notte a mezzanotte. Questi lavori possono portare a una grande variabilità nella latenza del processamento delle richieste. Il lavoro è anche più affidabile se l'attuale bucket ha ricevuto un numero simile di osservazioni a quello storicamente previsto.
Le anomalie nel mondo reale spesso mostrano l'impatto di vari fattori. La sezione Spiegazione dell'anomalia nel Single Metric Viewer può aiutarti a interpretare un'anomalia nel suo contesto.